f:id:Hiromi_Goto:20210312103110p:plain
view page
【12/26までP20倍!】【送料無料】味の素KK プロテインスープ コーンクリーム | プロテインみそ汁 AJINOMOTO スープ みそ汁 コーンスープ プロテイン たんぱく質 簡単…view page
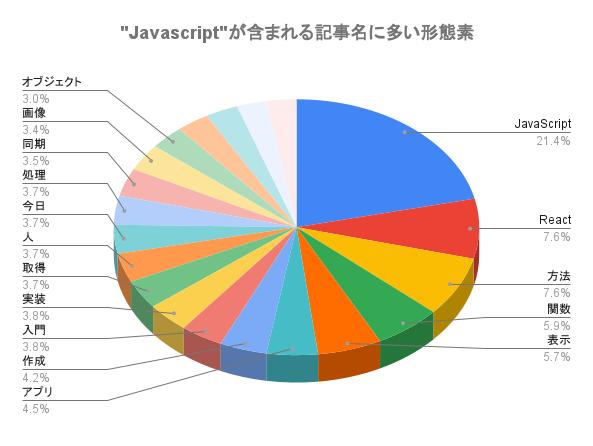
pythonで形態素解析エンジンMeCabを使って名詞の出現回数を数える
view page
【大感謝特価】 プロテイン カップケーキ 嫁にもろて プロテインマグケーキ おいしい ヘルシー ダイエット サポート スイーツ レモンチーズ チョコ 抹茶 低糖質 栄養 食物繊維 MCTオイル…view page
【公式】倖田來未 完全プロデュース キラーバーナー 2 機能性表示食品 ダイエットサプリ 1袋45粒入 送料無料【効果効能】体重 体脂肪 内臓脂肪 BMI ウエスト周囲 減少サポート エラグ酸…view page
Linux + Apache + MariaDB + Python ブログ
view page
Pythonでjanomeを使って形態素解析する方法(テキスト文書の品詞を数えテキストファイルやcsvファイルに保存する)
view page
【プロテインシェイカープレゼント!】 シックスパッド コアベルト 2 専用コントローラー付 公式ストア SIXPAD 腹筋 体幹 背筋 ながらトレーニング EMS シックスパッド…view page
u++の備忘録 言語処理100本ノック 2020「30. 形態素解析結果の読み込み」問題文問題の概要
view page
【全品20%OFFクーポン】【公式】《3か月集中セット》 MiiS ミーズ ホワイティエッセンス ホワイトニングジェル 歯の美容液 歯磨きジェル ホワイトニング ジェル 虫歯予防 自宅 簡単 口臭…view page
Python Janomeで形態素解析。読んだ本、経理データ、ブログ記事、アンケート、プロフィールを分析。
view page
ポイント15倍!(公式) 奇跡の歯ブラシ クリアブラック 正規品 歯ブラシ 虫歯予防 口臭予防 口臭ケア 歯垢除去 ホワイトニング 歯間 オーラルケア 日本製 HaRENO ハレノ 公式view page
Rustによる自然言語処理ツールの実装: 形態素解析器「sudachi.rs」
view page
TOPPAN%E3%82%A8%E3%83%83%E3%82%B8%E3%83%BB%E3%83%9A%E3%82%A4%E3%83%A1%E3%83%B3%E3%83%84%E6%A0%AA%E5%BC%8F%E4%BC%9A%E7%A4%BE 特許 特許情報・特許分析レポート
view page
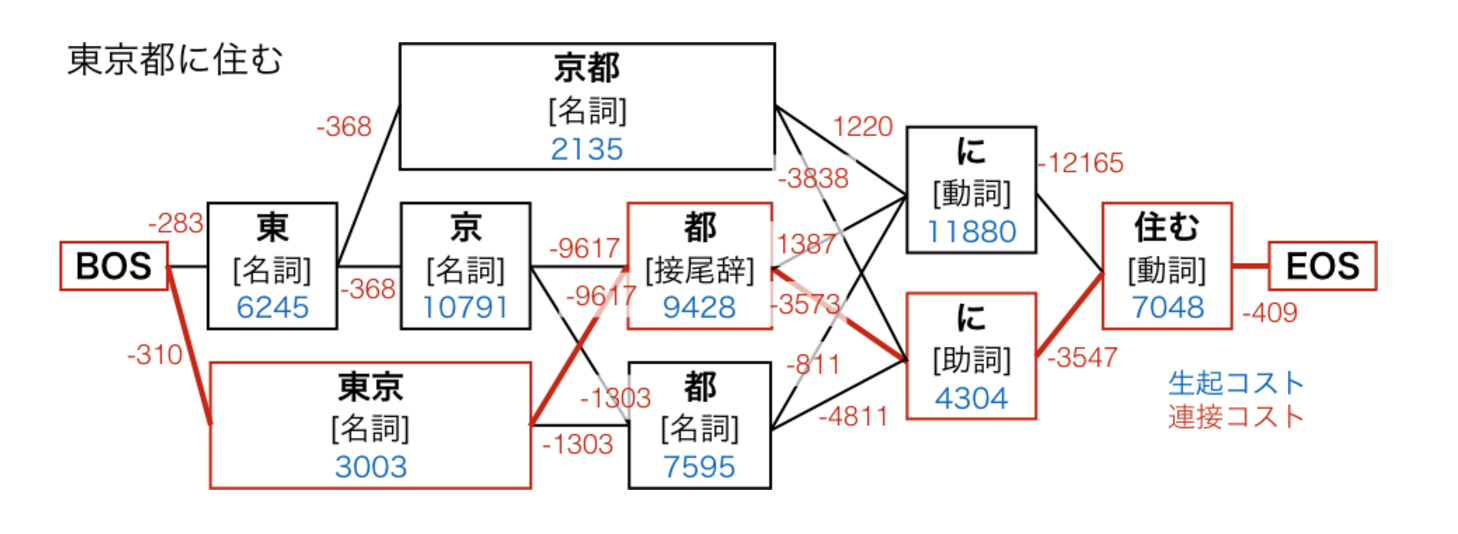
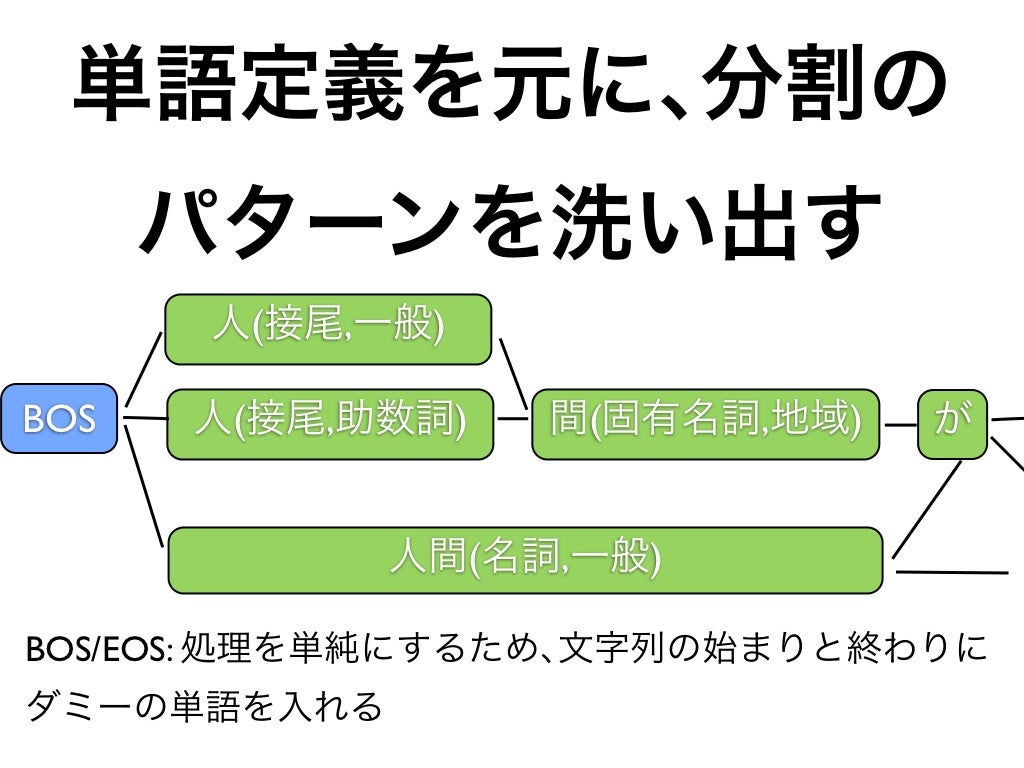
R による日本語テキスト前処理 (形態素解析を中心に)はじめに誰?著書(共著)今日の話パッケージ名だけでも覚えて帰ってくださいねテキストマイニングの全体像テキストデータの解析(引用)テキストデータ特有の処理パッケージ的には?テキストデータのモデリングR パッケージ的には?僕らがまず目指すところ単語がスペースで区切られてる状態(分かち書き)分かち書きされていれば、たいていのことはできてしまいます。 (ただし日本語は注意が必要)例: Bag of Words例: Bag of Words例: ストップワードの除去例: TF-IDF例: 機械学習モデル形態素解析について(日本語の)形態素解析の要素形態素解析の仕組み(ざっくり)形態素解析の仕組み(図解)コストの求め方と辞書の性能で形態素解析の精度が決まるこのへんをいい感じにやってくれるのが形態素解析器形態素解析器(有名なもの)MeCabJUMAN++Kytea形態素解析 (R 編)使える形態素解析器RMeCab パッケージ使ってみる単純な形態素解析余談どういうことかリストの状態ではアクセス方法が違うunlist()しちゃえば同じunlist()しちゃえば同じ話を戻してできた!!データフレームに適用したいrowwise()をかませますRMeCab は他にもいろいろできるrjumanpp パッケージ作者は私です使ってみる分かち書きの関数、ありますmecab_wakatiと比較JUMAN++独自の機能データフレーム欠点サーバーモードってやるのは面倒くさいですよね?関数を用意しましたちょっと速くなる時間を比較サーバーは解析が終わったら閉じるまとめパッケージの使い分けこのスライドについてEnjoy !!
view page
\15%OFFクーポン/【 繰り返し使える 】 アイマスク 充電式 ホットアイマスク アイピロー ホットアイピロー リラックス ギフト かわいい USB シルク 安眠 睡眠 快眠 グッズ 誕生日…view page
スキルアップしたい社会人のための情報サイト形態素解析とは?おすすめの5大解析ツールや実際の応用例を紹介
view page
【 Lypo-C 公式 】新発売 リポ カプセル ビタミンC+D (28包入) ×1箱 リポソーム ビタミンC ビタミンD ビタミンD3 サプリ リポC リポソーム ビタミン [1包…view page
【大感謝祭 限定 20%OFF】妊活×葉酸 妊活サプリ 妊活 サプリ マカ 葉酸サプリ 妊活サプリメント 無添加 葉酸 亜鉛 マカ 鉄 妊活 サプリ 男性 亜鉛 サプリメント ベルタプレリズム…view page
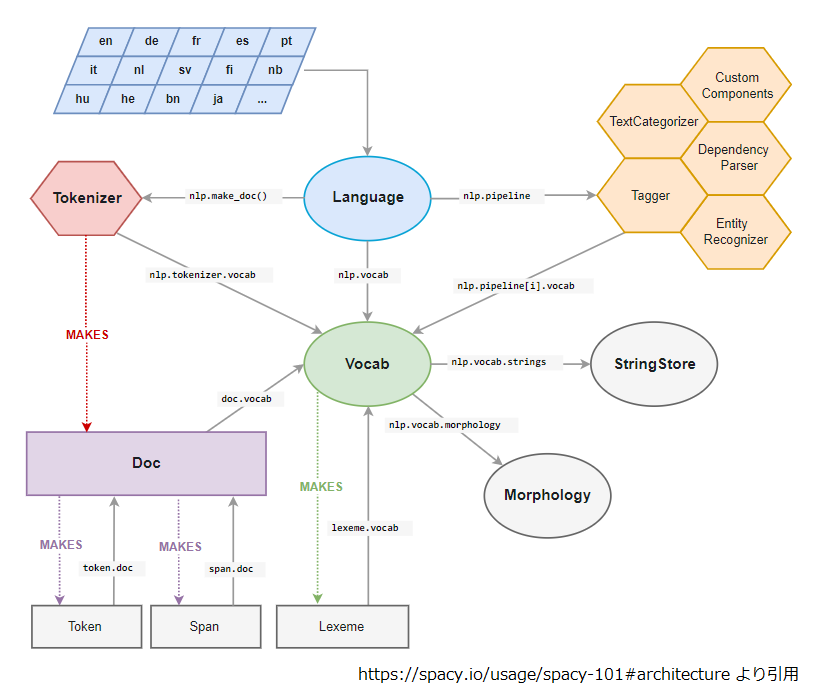
spaCy + GiNZAではじめて形態素解析してみたWhat is this?実施環境spaCyとは?GiNZAとは?実行環境のセットアップ使い方参考文献
view page
QiitaAPIと日本語形態素解析APIを使ってQiitaで人気のワードを探そう!
view page
シルク保湿マスク シルクマスク ネックウォーマー 寝る時 おやすみマスク 就寝用 レディース おしゃれ 日本製 就寝 蒸れにくい 洗える 温活 寝るとき 冷え対策 乾燥対策 喉のケア 秋 冬…view page
【ポイント10倍 12/19(金) 20:00〜12/26(金) 1:59まで】プレミアムカロリミット<機能性表示食品>【ファンケル 公式】 [FANCL ダイエット サポート サプリメント…view page
自然言語処理の前処理とMeCab(形態素解析エンジン)についてはじめに自然言語処理の前処理について形態素解析についてまとめ参考サイト
view page
【解説動画📺あり】N階マルコフ連鎖について、文章自動生成を題材に図解で解説!解説動画もあります!(むしろ動画がメインです)文章自動生成とは?形態素解析とは?(N階)マルコフ連鎖とは?文章自動生成の流れをおさえよう!「N階」マルコフ連鎖の「N階」とは?おわりに
view page
本日終了\P2倍/ プロテイン 女性 ダイエット 栄養機能食品 ソイプロテイン プロテインダイエット 置き換えダイエット 置き換え シェイク ファスティング タンパク質 低糖質 低脂質…view page
【今だけポイント10倍!】【 公式:上野水香プロデュース 】コアウォークサポーター アジャスト 足裏アーチ 足裏 サポーター フットサポーター 土踏まず アーチサポーター ヨガソックス 5本指…view page
























![【 Lypo-C 公式 】新発売 リポ カプセル ビタミンC+D (28包入) ×1箱 リポソーム ビタミンC ビタミンD ビタミンD3 サプリ リポC リポソーム ビタミン [1包 ビタミンC&Dを効率良く吸収 国内製造] 液状 サプリメント 個包装 T](https://thumbnail.image.rakuten.co.jp/@0_mall/lypoc/cabinet/item/11432931/imgrc0091417505.jpg?_ex=300x300)





![【ポイント10倍 12/19(金) 20:00〜12/26(金) 1:59まで】プレミアムカロリミット<機能性表示食品>【ファンケル 公式】 [FANCL ダイエット サポート サプリメント キトサン カロリー サプリ 健康食品 桑の葉 くわのは サポニン 女性 男性 血中中性脂肪 40代 ヘルスケア]](https://thumbnail.image.rakuten.co.jp/@0_mall/fancl-shop/cabinet/thanks/thx_20251219/precalo_p10.jpg?_ex=300x300)