



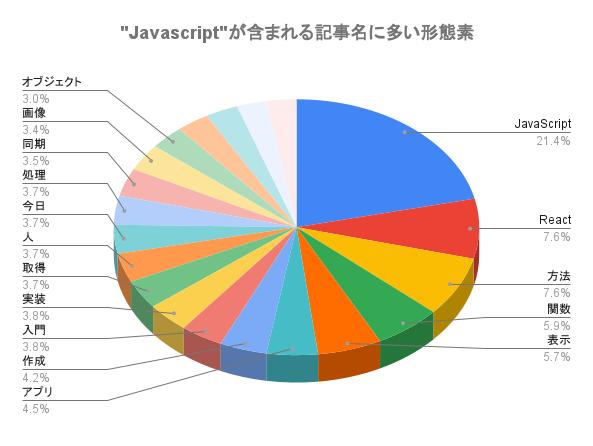
















特典付き! 分別ごみ箱 【 ソロウ ペダルオープン ツイン 45L 35L 20L スリム 13L ワイド45L 】 SOLOW 45リットル 35リットル 20リットル ふた付き 蓋つき 両開き ペダル付き 足踏み ゴミ袋 抗菌 キッチン カウンター下 公式 おしゃれ シンプル 白 黒 グレー RISU
3,080円
4571 customer ratings
4.52 ★★★★★
「キッチンの棚下やカウンター下のスペースにぴったり」 軽い踏み心地でパカっと左右に開くツイン蓋が使いやすいダストボックス。 両開きだからコンパクトにフタを全開することができます。 抗菌・防汚加工がされているのでキッチンでのご使用も安心。 GSLW011 GSLW012 GSLW013…

![[本日P5倍] マットレス 高反発 シングル 三つ折りマットレス 敷布団 敷き布団 三つ折り 高反発マットレス セミダブル ダブル 極厚10cm 3つ折り 消臭 メッシュ生地 ベッドマットレス シングルマットレス セミダブルマットレス ダブルマットレス](https://thumbnail.image.rakuten.co.jp/@0_mall/dondon/cabinet/xlm005_9.jpg?_ex=145x145)





![[数量限定] 半額クーポン1/1-1/3 【ZIP!キテルネで紹介されました!】 毛布 NERUS 【正規品】 ふわとろ毛布 もこもこ毛布 ブランケット モコモコ とろとろ ふわふわ 毛布 シングル セミダブル ダブル ハーフ ふわもこ ポコポコ ひざ掛け 2枚合わせ 厚手 秋冬 Branchpoint](https://thumbnail.image.rakuten.co.jp/@0_mall/t-interior/cabinet/item/usual/htc18_a.jpg?_ex=145x145)















