Category:強化学習

SARSA法
State–action–reward–state–action
エンドツーエンドの強化学習
End-to-end reinforcement learning
DQN (コンピュータ)
モデルフリー (強化学習)
Model-free (reinforcement learning)
分布ソフト・アクター・クリティック法
Distributional Soft Actor Criticベイズ強化学習
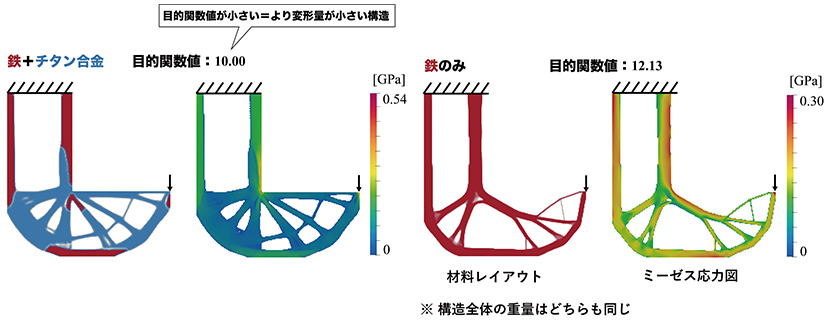
近接方策最適化
Proximal policy optimization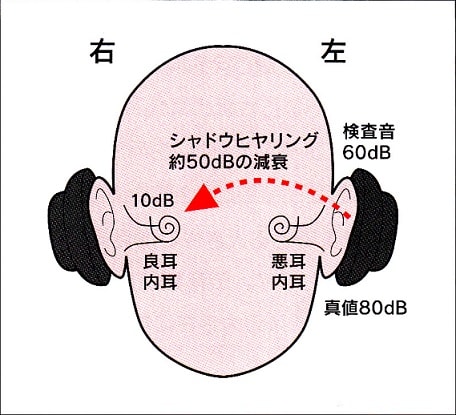
時間差分学習
Temporal difference learning階層型強化学習
人間のフィードバックによる強化学習
Reinforcement learning from human feedback強化学習
Reinforcement learning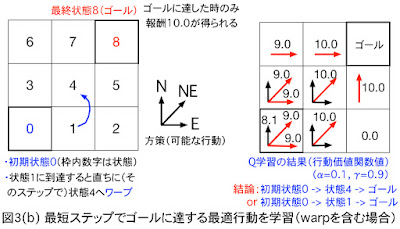
Q学習
Q-learning