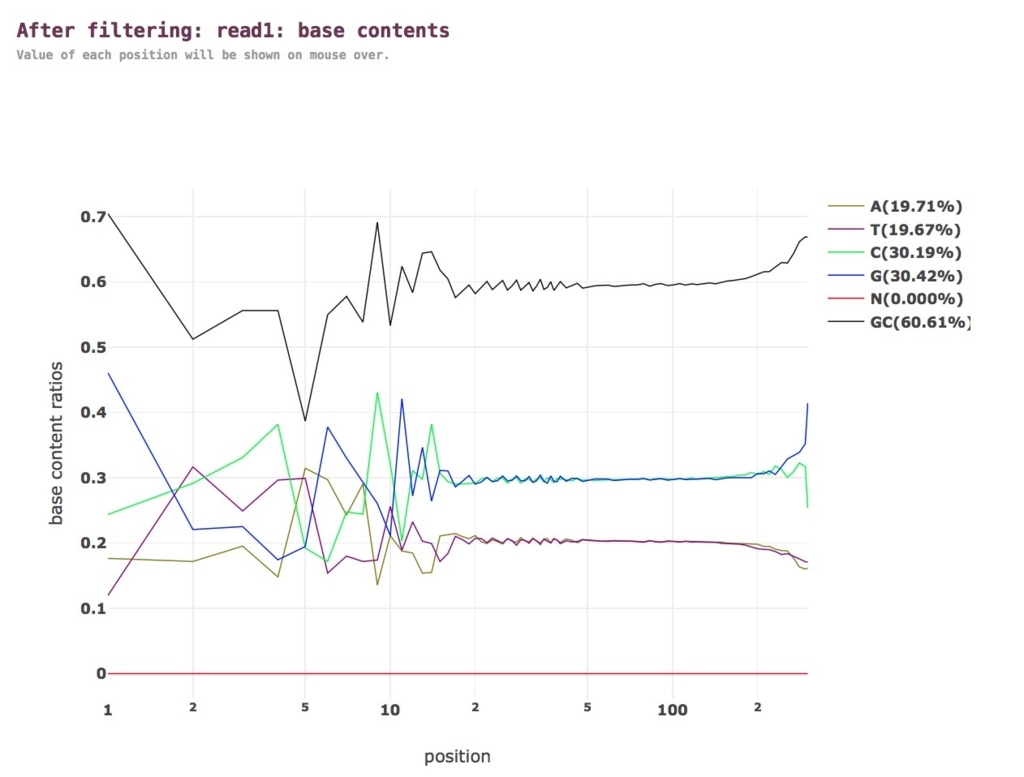
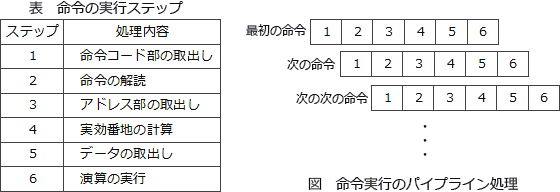
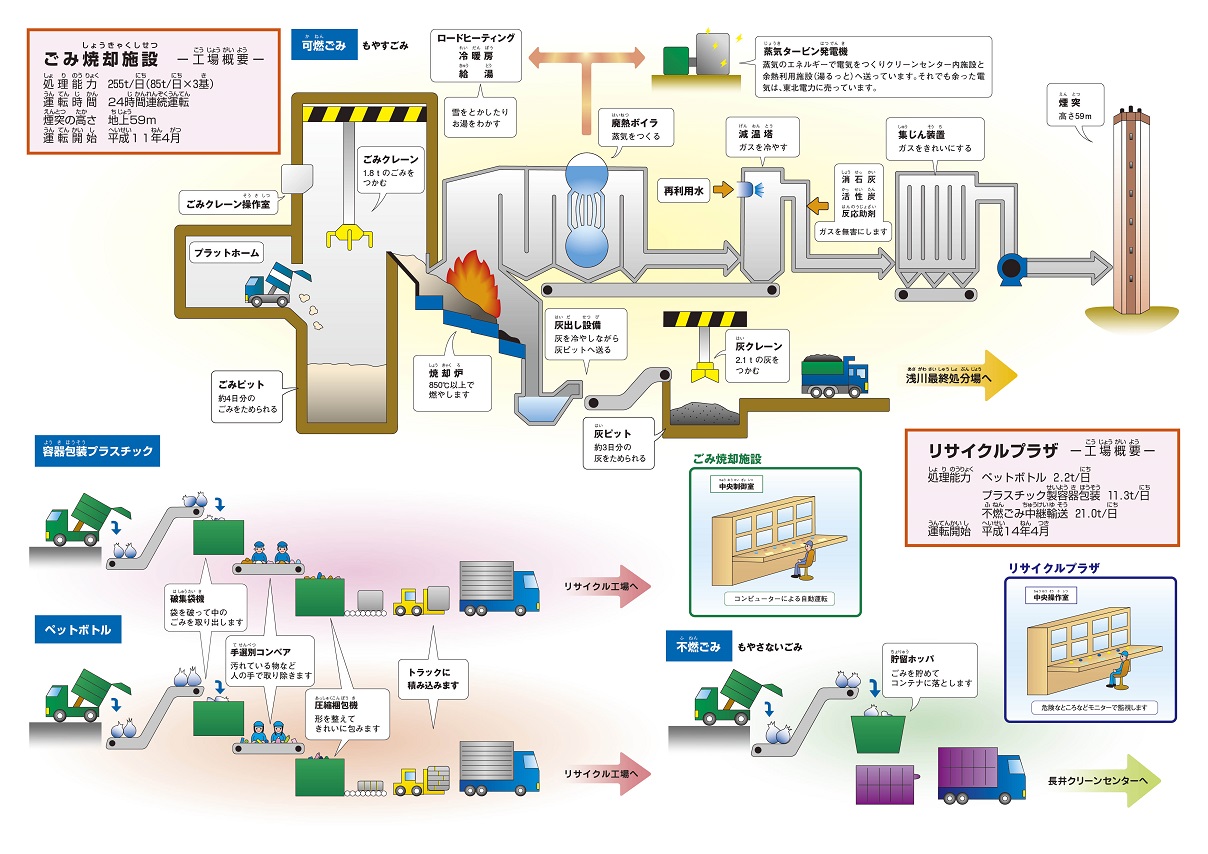
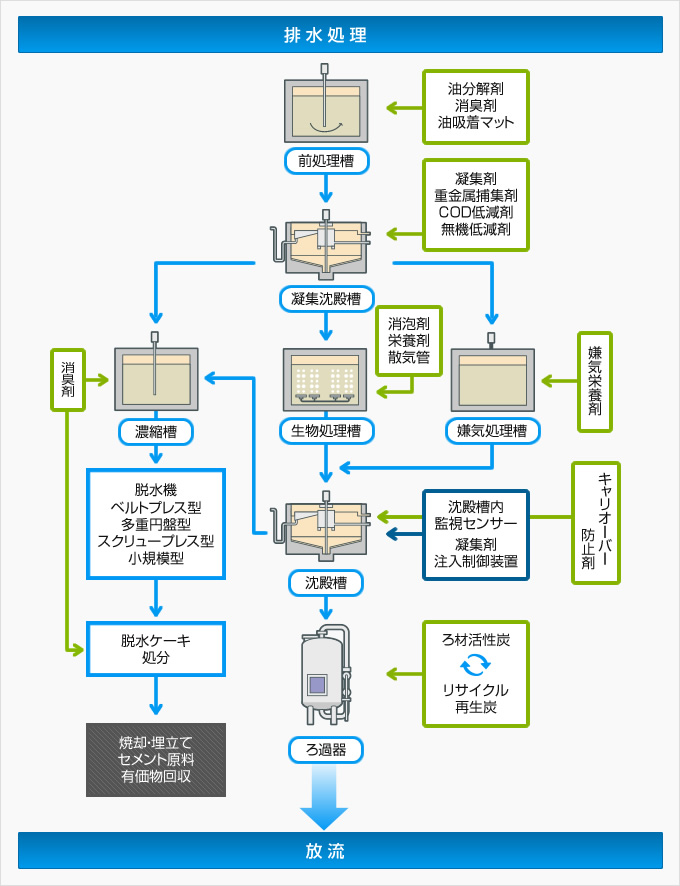
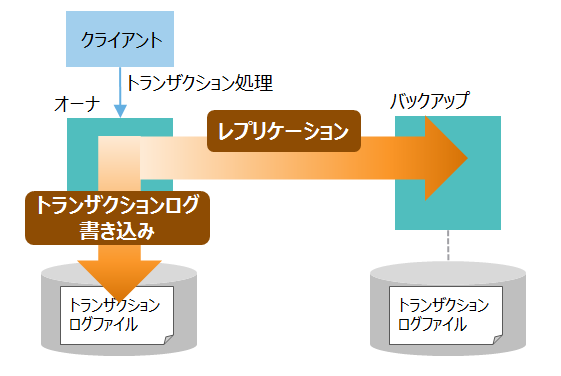
Images of オンライン処理





![\ランキング1位/シャープ 空気清浄機 FU-S50-W プラズマクラスター7000 ホワイト系 SHARP [空気清浄機 ~23畳] 花粉 スピード循環気流 脱臭 集じん PM2.5対応 FU-R50-W FU-R50の後継 リビング 寝室 新生活 薄型 fus50 FUS50 【KK9N0D18P】 エクプラ特選](https://thumbnail.image.rakuten.co.jp/@0_mall/a-price/cabinet/mailmaga/08814302/2980000205750.jpg?_ex=300x300)



![【公式店は2年保証】電子レンジ 17L レンジ 家電 小型 650W 500W 200W ターン ターンテーブル アイリスオーヤマ ホワイト ブラック 白 黒 シンプル 一人暮らし ひとり暮らし 新生活 単機能 単機能レンジ コンパクト おしゃれ [安心延長保証対象]](https://thumbnail.image.rakuten.co.jp/@0_mall/irisplaza-r/cabinet/11073544/12782397/12918968/100943.jpg?_ex=300x300)



![【公式店は2年保証】炊飯器 3合炊き 5合炊き 5.5合 マイコン おいしい シンプル ミニ おしゃれ 炊飯ジャー 一人暮らし ひとり暮らし用 早炊き エコ炊飯 節電 マイコン炊飯器 新生活 ホワイト ブラック 白 黒 アイリスオーヤマ RC-BMA30 RC-BMA50 *[安心延長保証対象]](https://thumbnail.image.rakuten.co.jp/@0_mall/irisplaza-r/cabinet/10172579/imgrc0110735052.jpg?_ex=300x300)



![\高品質 高コスパ/ 冷蔵庫 マット 冷蔵庫マット 冷蔵庫下マット クリア 透明 床暖房 キズ 凹み 防止 下敷き ポリカーボネート 洗濯機 SNSで大人気 [S/M/L] [ゼロキーパー]](https://thumbnail.image.rakuten.co.jp/@0_mall/e-kit/cabinet/description/ek-kbmr01mcl/ek-kbmr01_1.jpg?_ex=300x300)
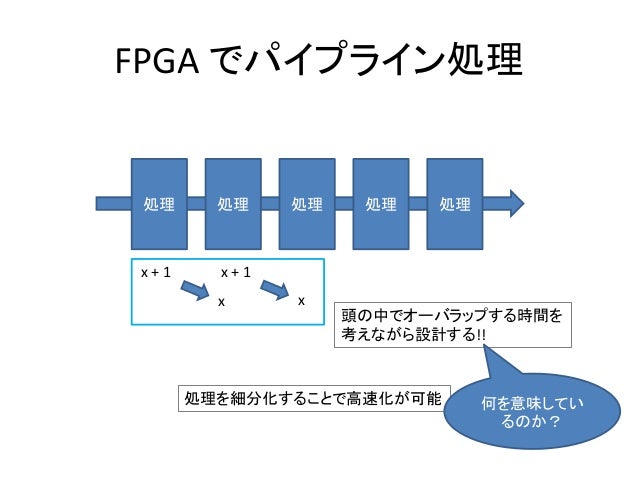
![FFTは前述しているように性能を優先するため、入力から出力まで大小のパイプラインを連ねて構成します。先ず全体像となる大きなパイプラインを考えます。
大きなパイプラインのステージ分け[1]は、データの塊をバッファする前後の処理で分けると考えやすいと思います。ここでは、SRAMへのデータ入力→SRAM間のRadix-4を用いたバタフライ計算の繰り返し→SRAMからのデータ出力の3ステージとします。またそれぞれ、LoadData, BfCalc, StoreDataと命名け[2]します。
入出力のインターフェイスは、未知の外部モジュールとの接続を考慮するといくらかの柔軟性が必要です。このような柔軟性はメモリ接続が参考になります。これに基づいてリクエスト(起動)制御とデータ制御を分離します(それぞれのパイプラインは非同期制御になります)。
3つのステージの制御ですが、スループット制御の入力制御タイプ?を使います。これにより、それぞれのステージが処理を終えるまでパラメータがHold制御されます。これを採用する理由は、将来的にFFTの起動ごとに変換するサンプル数や逆変換など自由に変えることができるようにしたいためです。参考に、パラメータのページも参照して下さい。
なお、性能向上とStall系の伝搬を遮断するため、ステージ間にはFIFOを挿入します。挿入しないと前段のLoadDataはStallが重なり合い、動作可能なのに動作できず、無駄なWaitサイクルが生じてしまいます。
リクエストパイプから起動後(iVld)、データパイプからデータを引き抜きSRAMに書き込みます。上記で述べたようにデータ入力が終了するまで、リクエストパイプはHoldします(iStall)。
入力データをカウントし、その値をアドレスに変換してSRAMアクセスする方法が簡単です。しかし、将来的には2の累乗に足りないものや入力位置オフセットに対処するには、絶対的な位置情報を予め作っておく方が便利です。ここでは、起動後にFFTのポイント数をカウント(cnt)する部分を設け、これでパイプラインを駆動するようにします。
カウンタをBit Reverseしデータアドレスを生成します。また、BfCalcの初段のSRAM Bankの攪拌に合わせてSRAMアドレスを生成します。生成したSRAMアドレスと入力データをSRMAに出力します(?)。
カウンタを起点にするパイプとデータパイプの結合を行います(?)。コスト的にデータラッチの回数が少なくなるよう、結合部はSRAMアクセスに近い部分が適しますが、データのフォーマット変換等(Int→Floatなど)のため1ステージ程度の余裕を設けておきます(?)。
カウンタを用いた組み合わせ回路による結合制御は、遅延伝搬を避けるため必須ではありませんがバッファに挟まれるようにします(?)。
なお、パイプラインの入力でパラメータはHoldするものの、異なるパラメータのFFTを連続処理するとパイプラインの中には異なる2つの処理が存在することになります。従って、必要なパラメータは順にパイプラインに流さなければなりません。これがパイプラインにバブルを発生させない秘訣です。逆に言うと、常に同じパラメータを使う場合や、一旦FFTの処理が全て終えるまでパラメータを切り替えない条件を与えれば不要です。
機能的にLoadDataと同じなので、基本的に構成も同じになります。異なるのは、リクエストパイプから起動後直ちにSRAMアクセスを行い、取得したデータをデータパイプに出力することです。また、Bit Reverseは行いません。
SRAMのアクセス(Read Enableとアドレスをアサート)とデータ取得は、SRAMのSetupタイミングに余裕を与えるため前後にバッファを挿入します(?)。
リクエストパイプとデータパイプ間には、SRAMと平行にパラメータを伝達するためのバッファ(?)を置きます。両者は同一パイプラインとして同期制御します。
SRAMは直接Stall制御できないため、例えば、SRAMモデルのRead Enable信号(RE)に後続ステージのStall信号を加味[3]しなければなりません。ステージの構造の基本型(S?)もしくはバッファ型(S?)の図中のデータFFのCEの接続を参考にして下さい。
Radix-4のバタフライ演算の本体になります。と言っても難しくはありません。仕組みはLoadDataとStoreDataを合わせたものであり、パイプラインに演算器を挟む形になります。
下図に示す通り、StoreDataと同じ構造のカウンタ発生部とSRAM読み出し部、演算パイプ、LoadDataと同じ構造のSRAM書き込み部(カウンタ発生部は削除)の構成になります。
少し違うのは、サンプル数のカウントに加え、Phaseのカウントを行う点と、前ページで述べたようにPhaseの切り替わり時に処理を何もしない期間のGAPを加える点です。
SRAMは2ポートSRAMなのでReadとWriteの同時アクセスそのものは問題ないのですが、これから使おうとする値を上書きされては困ります。特にFFTのデータアドレッシングは、Phase間でシャッフルされるので未Read部分へのWriteが必ず発生します。従ってSRAM容量は増えますが、Read側とWrite側のアドレス空間を分け、PhaseごとにSRAM領域をPing-pongアクセスさせます。LoadDataとStoreDataが同時アクセスするための2重化と違うので注意して下さい(Ping-pongは同一SRAMに対して実施)。
ところで見て分かるように、Phaseの数(log4N)が奇数だとLoadDataで格納した領域に結果が、偶数だと反対側の領域に結果が格納されます。従ってBfCalcはもちろんLoadDataとStoreDataも、過去の処理したサンプル数によりSRAMの格納領域をそれぞれ制御しなければなりません[4]。分かりにくいのですが、LoadDataの入力とStoreDataの出力が同時に動作することを考えると(最大性能を出すためパイプライン処理化)、それぞれの格納領域は排他的な位置になるようにします。
Radix-4のバタフライ演算の実体ですが、下図のように4段の半精度浮動小数点演算器を並べた構造になります。1つ当たり2サイクル必要なので、並走するリクエストパイプ(遅延パイプ)は8段になります。Load側で3サイクル、Store側で0サイクル(バッファは左記の8段に含まれる)必要なので、合計11サイクルのレイテンシを持ったパイプラインになります。
入力データと三角関数の係数(後述)との複素数乗算で、4個のfmulと2個のfaddを使用します。4セット必要ですが、最初の係数は(Re=1, Im=0)になるので1セット分は省略[5]できます(図の括弧は省略しなかった場合の数)。また、回転行列は4セット分の処理で、合計16個のfaddを使用します。回転行列の特性からReとImの交換・符号反転が行えるので乗算器は使用しません[6]。
三角関数の係数は、サンプル数とPhaseのカウンターを元にROM参照します。ROMはsinθを記述で回転因子分(0〜π/4)羅列しておきます。SRAMのデータ出力のタイミングを合わせて参照します。参照モジュールはサンプルコードを見て下さい。なお、モジュールはsinθテーブルから与える指標を操作して複素数の係数を導き出します。
SRAMは2セット構成になることは前のページで触れましたが、単純にユニットのSRAMに対する信号をマージすると、同一SRAMへの要求信号が重なり合い誤ったSRAMアクセスが発生してしまいます。
リクエストの衝突を避けるには、SRAMの状態を把握し各ステージの入り口の起動をブロックする方法(?)と、SRAMアクセス時にStallを掛ける方法(?)が考えられます。ここでは制御が簡単な前者の方法を考えます[7]。
大きなパイプラインの流れをよく考えると、以下の条件が導き出せます。
2ポートSRAMを使用するため、Read対Read、Write対Writeのアクセスの回避が必要
→LoadDataとBfCalc、StoreDataとBfCalcの組み合わせチェックを実施
LoadData、BfCalc、StoreDataは処理の終了をもってリレーし、追い越しは生じない
→リクエストの衝突は異なるFFT処理でしか発生せず、ユニット間のチェックの方向が定まる(BfCalc→LoadData、StoreData→BfCalc)
2セットのSRAMを用いたダブルバッファ制御の実施
→リクエストの衝突は使用するセット番号が異なれば生じない
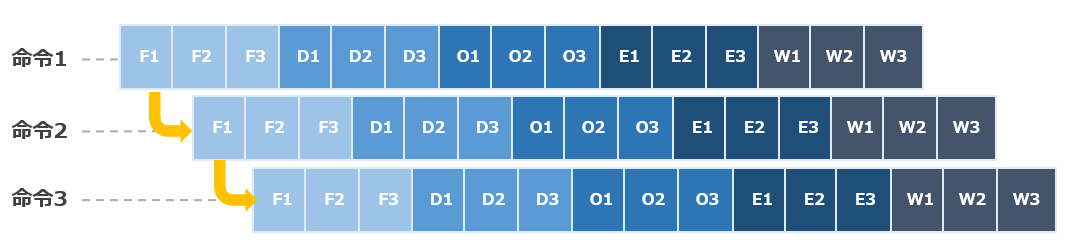
具体的には下図のようにFFTを4つ連続して処理する場合、同一セットで生じるBfCalc→LoadData、StoreData→BfCalcの衝突を検知し起動をブロックするだけです。ユニット間はパイプライン接続により、終了後自動的に接続します。なお、LoadDataの処理はLD、BfCalcの処理はBC、StoreDataの処理はSTの箱で示しています。
ブロック制御ですが、ダブルバッファなので2つの状態制御を用意します。それぞれが1つのSRAMの状態を示します。各ユニットのパイプラインの出口をモニタし遷移させます。](https://architek.ai/old/design/images/FFTWave1.png)
FFTは前述しているように性能を優先するため、入力から出力まで大小のパイプラインを連ねて構成します。先ず全体像となる大きなパイプラインを考えます。 大きなパイプラインのステージ分け[1]は、データの塊をバッファする前後の処理で分けると考えやすいと思います。ここでは、SRAMへのデータ入力→SRAM間のRadix-4を用いたバタフライ計算の繰り返し→SRAMからのデータ出力の3ステージとします。またそれぞれ、LoadData, BfCalc, StoreDataと命名け[2]します。 入出力のインターフェイスは、未知の外部モジュールとの接続を考慮するといくらかの柔軟性が必要です。このような柔軟性はメモリ接続が参考になります。これに基づいてリクエスト(起動)制御とデータ制御を分離します(それぞれのパイプラインは非同期制御になります)。 3つのステージの制御ですが、スループット制御の入力制御タイプ?を使います。これにより、それぞれのステージが処理を終えるまでパラメータがHold制御されます。これを採用する理由は、将来的にFFTの起動ごとに変換するサンプル数や逆変換など自由に変えることができるようにしたいためです。参考に、パラメータのページも参照して下さい。 なお、性能向上とStall系の伝搬を遮断するため、ステージ間にはFIFOを挿入します。挿入しないと前段のLoadDataはStallが重なり合い、動作可能なのに動作できず、無駄なWaitサイクルが生じてしまいます。 リクエストパイプから起動後(iVld)、データパイプからデータを引き抜きSRAMに書き込みます。上記で述べたようにデータ入力が終了するまで、リクエストパイプはHoldします(iStall)。 入力データをカウントし、その値をアドレスに変換してSRAMアクセスする方法が簡単です。しかし、将来的には2の累乗に足りないものや入力位置オフセットに対処するには、絶対的な位置情報を予め作っておく方が便利です。ここでは、起動後にFFTのポイント数をカウント(cnt)する部分を設け、これでパイプラインを駆動するようにします。 カウンタをBit Reverseしデータアドレスを生成します。また、BfCalcの初段のSRAM Bankの攪拌に合わせてSRAMアドレスを生成します。生成したSRAMアドレスと入力データをSRMAに出力します(?)。 カウンタを起点にするパイプとデータパイプの結合を行います(?)。コスト的にデータラッチの回数が少なくなるよう、結合部はSRAMアクセスに近い部分が適しますが、データのフォーマット変換等(Int→Floatなど)のため1ステージ程度の余裕を設けておきます(?)。 カウンタを用いた組み合わせ回路による結合制御は、遅延伝搬を避けるため必須ではありませんがバッファに挟まれるようにします(?)。 なお、パイプラインの入力でパラメータはHoldするものの、異なるパラメータのFFTを連続処理するとパイプラインの中には異なる2つの処理が存在することになります。従って、必要なパラメータは順にパイプラインに流さなければなりません。これがパイプラインにバブルを発生させない秘訣です。逆に言うと、常に同じパラメータを使う場合や、一旦FFTの処理が全て終えるまでパラメータを切り替えない条件を与えれば不要です。 機能的にLoadDataと同じなので、基本的に構成も同じになります。異なるのは、リクエストパイプから起動後直ちにSRAMアクセスを行い、取得したデータをデータパイプに出力することです。また、Bit Reverseは行いません。 SRAMのアクセス(Read Enableとアドレスをアサート)とデータ取得は、SRAMのSetupタイミングに余裕を与えるため前後にバッファを挿入します(?)。 リクエストパイプとデータパイプ間には、SRAMと平行にパラメータを伝達するためのバッファ(?)を置きます。両者は同一パイプラインとして同期制御します。 SRAMは直接Stall制御できないため、例えば、SRAMモデルのRead Enable信号(RE)に後続ステージのStall信号を加味[3]しなければなりません。ステージの構造の基本型(S?)もしくはバッファ型(S?)の図中のデータFFのCEの接続を参考にして下さい。 Radix-4のバタフライ演算の本体になります。と言っても難しくはありません。仕組みはLoadDataとStoreDataを合わせたものであり、パイプラインに演算器を挟む形になります。 下図に示す通り、StoreDataと同じ構造のカウンタ発生部とSRAM読み出し部、演算パイプ、LoadDataと同じ構造のSRAM書き込み部(カウンタ発生部は削除)の構成になります。 少し違うのは、サンプル数のカウントに加え、Phaseのカウントを行う点と、前ページで述べたようにPhaseの切り替わり時に処理を何もしない期間のGAPを加える点です。 SRAMは2ポートSRAMなのでReadとWriteの同時アクセスそのものは問題ないのですが、これから使おうとする値を上書きされては困ります。特にFFTのデータアドレッシングは、Phase間でシャッフルされるので未Read部分へのWriteが必ず発生します。従ってSRAM容量は増えますが、Read側とWrite側のアドレス空間を分け、PhaseごとにSRAM領域をPing-pongアクセスさせます。LoadDataとStoreDataが同時アクセスするための2重化と違うので注意して下さい(Ping-pongは同一SRAMに対して実施)。 ところで見て分かるように、Phaseの数(log4N)が奇数だとLoadDataで格納した領域に結果が、偶数だと反対側の領域に結果が格納されます。従ってBfCalcはもちろんLoadDataとStoreDataも、過去の処理したサンプル数によりSRAMの格納領域をそれぞれ制御しなければなりません[4]。分かりにくいのですが、LoadDataの入力とStoreDataの出力が同時に動作することを考えると(最大性能を出すためパイプライン処理化)、それぞれの格納領域は排他的な位置になるようにします。 Radix-4のバタフライ演算の実体ですが、下図のように4段の半精度浮動小数点演算器を並べた構造になります。1つ当たり2サイクル必要なので、並走するリクエストパイプ(遅延パイプ)は8段になります。Load側で3サイクル、Store側で0サイクル(バッファは左記の8段に含まれる)必要なので、合計11サイクルのレイテンシを持ったパイプラインになります。 入力データと三角関数の係数(後述)との複素数乗算で、4個のfmulと2個のfaddを使用します。4セット必要ですが、最初の係数は(Re=1, Im=0)になるので1セット分は省略[5]できます(図の括弧は省略しなかった場合の数)。また、回転行列は4セット分の処理で、合計16個のfaddを使用します。回転行列の特性からReとImの交換・符号反転が行えるので乗算器は使用しません[6]。 三角関数の係数は、サンプル数とPhaseのカウンターを元にROM参照します。ROMはsinθを記述で回転因子分(0〜π/4)羅列しておきます。SRAMのデータ出力のタイミングを合わせて参照します。参照モジュールはサンプルコードを見て下さい。なお、モジュールはsinθテーブルから与える指標を操作して複素数の係数を導き出します。 SRAMは2セット構成になることは前のページで触れましたが、単純にユニットのSRAMに対する信号をマージすると、同一SRAMへの要求信号が重なり合い誤ったSRAMアクセスが発生してしまいます。 リクエストの衝突を避けるには、SRAMの状態を把握し各ステージの入り口の起動をブロックする方法(?)と、SRAMアクセス時にStallを掛ける方法(?)が考えられます。ここでは制御が簡単な前者の方法を考えます[7]。 大きなパイプラインの流れをよく考えると、以下の条件が導き出せます。 2ポートSRAMを使用するため、Read対Read、Write対Writeのアクセスの回避が必要 →LoadDataとBfCalc、StoreDataとBfCalcの組み合わせチェックを実施 LoadData、BfCalc、StoreDataは処理の終了をもってリレーし、追い越しは生じない →リクエストの衝突は異なるFFT処理でしか発生せず、ユニット間のチェックの方向が定まる(BfCalc→LoadData、StoreData→BfCalc) 2セットのSRAMを用いたダブルバッファ制御の実施 →リクエストの衝突は使用するセット番号が異なれば生じない 具体的には下図のようにFFTを4つ連続して処理する場合、同一セットで生じるBfCalc→LoadData、StoreData→BfCalcの衝突を検知し起動をブロックするだけです。ユニット間はパイプライン接続により、終了後自動的に接続します。なお、LoadDataの処理はLD、BfCalcの処理はBC、StoreDataの処理はSTの箱で示しています。 ブロック制御ですが、ダブルバッファなので2つの状態制御を用意します。それぞれが1つのSRAMの状態を示します。各ユニットのパイプラインの出口をモニタし遷移させます。