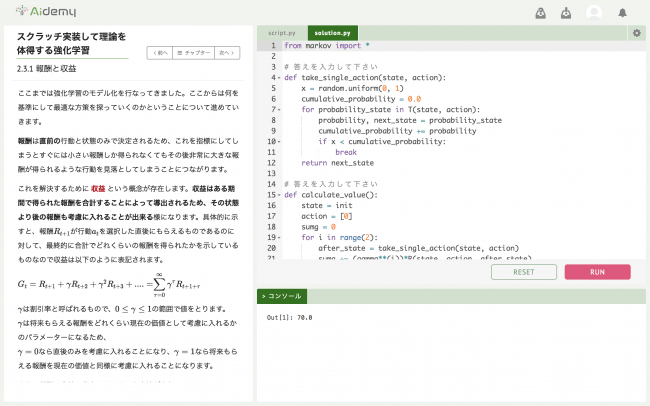
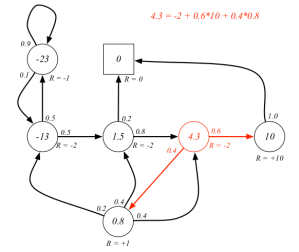
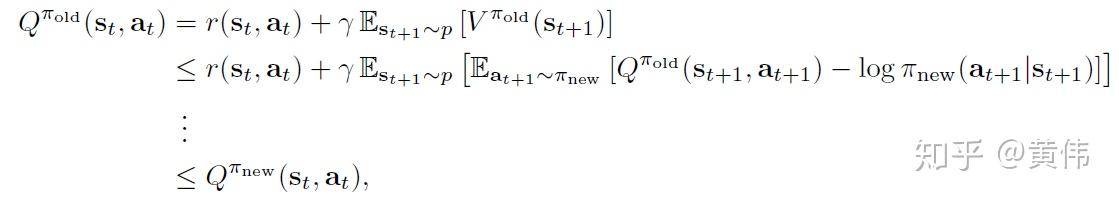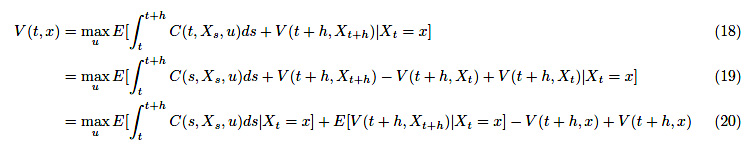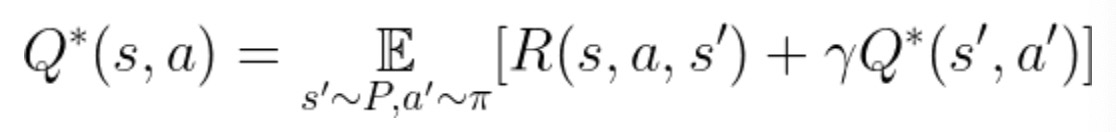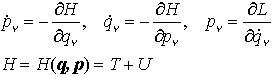からっぽのしょこ 3.5.1:ベルマン最適方程式の適用【ゼロつく4のノート】はじめに参考文献おわりに

【ふるさと納税】200-3【選べるカラー】高性能リユース スマホ Apple iPhone 13 128GB SIMロック解除済 本体のみ | 中古 再生品 本体 端末

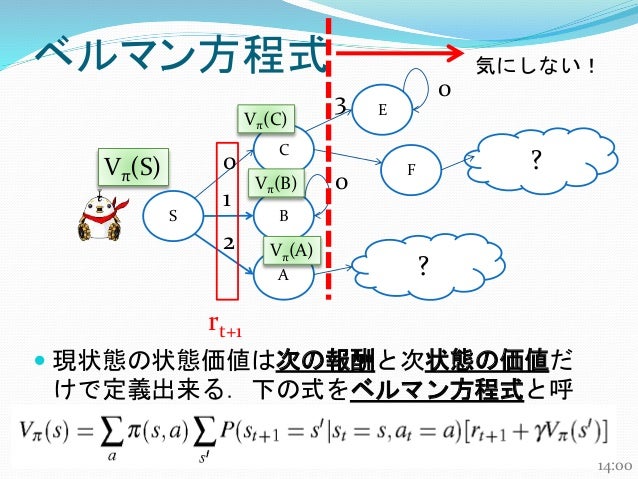
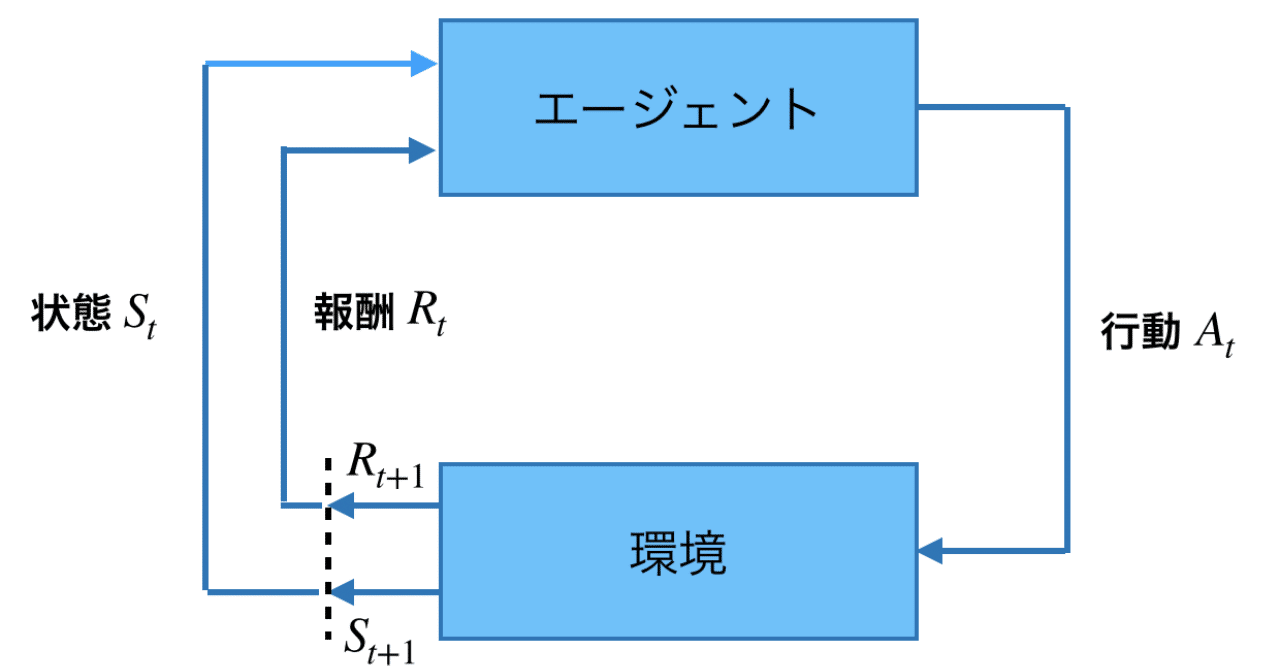
強化学習2 マルコフ決定過程・ベルマン方程式はじめに強化学習の構成要素マルコフ決定過程価値・収益・状態最適な方策の探索ベルマン方程式まとめ

最大5000円オフ【中古】iPhone 14 128GB 256GB 512GB A2881 スマホ スマートフォン 本体 SIMフリー ミッドナイト (PRODUCT)RED スターライト…
![[新品未開封|SIMフリー] iPhone 16 128GB 256GB 512GB 各色 スマホ 本体](https://thumbnail.image.rakuten.co.jp/@0_mall/icockaden/cabinet/10962912/11261694/iphone16-all.jpg?_ex=300x300)
[新品未開封|SIMフリー] iPhone 16 128GB 256GB 512GB 各色 スマホ 本体

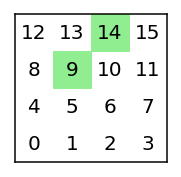
マルコフ決定過程とベルマン方程式 前書きマルコフ過程(マルコフ連鎖)マルコフ報酬プロセスマルコフ決定過程(MDP)Q値ベルマン最適方程式概要次は何ですか

f:id:mabonki0725:20170618093435p:plain

f:id:akifukka:20200125111703j:plain

最大5000円オフ【中古】iPhone SE 第3世代 2022 SE3 A2782 64GB 128GB スマホ スマートフォン SE3 本体 SIMフリー ミッドナイト レッド スターライト…

ソフトウェア系の雑記
詳解確率ロボティクス第11章(後半、n-step SarsaとSarsa(λ) )
コメント

マートンのポートフォリオ問題を解く1(HARA型効用とHJB方程式導出)

最大5000円オフ【中古】iPhone 13 128GB 256GB 512GB A2631 スマホ スマートフォン 本体 SIMフリー グリーン ピンク ブルー ミッドナイト スターライト…

最大5000円オフ純正バッテリー100%|90%【中古】iPhone 15 128GB 256GB 512GB A3089 スマホ スマートフォン 本体 SIMフリー ピンク イエロー グリーン…

ソフトウェア系の雑記
詳解確率ロボティクス第二章 後半その1
コメント

深層学習後編2 keras~強化学習 講義課題視聴レポート (現場で潰しが効くディープラーニング講座)

最大5000円オフ【中古】iPhone 12 64GB 128GB 256GB A2402 スマホ スマートフォン 本体 SIMフリー ブラック ブルー グリーン パープル レッド ホワイト…

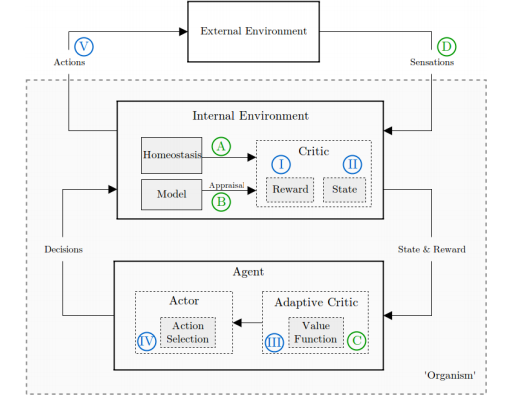
【強化学習】SARSA、Q学習の徹底解説&Python実装強化学習の基本的な枠組み価値反復に基づくアルゴリズム価値反復法OpenAIGymのFrozenLake問題を解く参考
![[新品未開封|未使用品|SIMフリー] iPhone 16e 128GB 256GB 512GB ホワイト ブラック アイフォン16e 本体 スマホ](https://thumbnail.image.rakuten.co.jp/@0_mall/icockaden/cabinet/202503/imgrc0186349549.jpg?_ex=300x300)
[新品未開封|未使用品|SIMフリー] iPhone 16e 128GB 256GB 512GB ホワイト ブラック アイフォン16e 本体 スマホ
f:id:mabonki0725:20170520060602p:plain

論文メモ Playing Atari with Deep Reinforcement Learning

【ふるさと納税】130-2【選べるカラー】高性能リユース スマホ Apple iPhone 12 64GB SIMロック解除済 本体のみ | 中古 再生品 本体 端末

からっぽのしょこ 3.4:ベルマン最適方程式【ゼロつく4のノート】はじめに参考文献おわりに

最大5000円オフ純正バッテリー100%|90%【中古】iPhone 13 128GB 256GB 512GB A2631 スマホ スマートフォン 本体 SIMフリー ミッドナイト…

iPhone 14 128GB ミッドナイト MPUD3J/A【即納】【あす楽】アイフォン 本体 のみ SIMフリー iphone14 アイフォン14 アイホン アイホン14 シムフリー スマホ…

マルコフ決定過程(MDP)を理解する 内容マルコフ性マルコフ過程またはマルコフ連鎖マルコフ報酬プロセス(MRP)マルコフ決定過程(MDP)戻る(G_t)ポリシー(π)値関数最適値関数結論参考文献

【新登場】iPhone 17 Pro simフリー 端末本体のみ (機種変更はこちら) 新品 純正 Apple 認定店 楽天モバイル公式 アイフォン…

ソフトウェア系の雑記
詳解確率ロボティクス第十章(前半、MDPとDP)
コメント

素人のための本格的強化学習 #2 強化学習基礎の実践 〜Q Learning〜① 準備

最大5000円オフ【中古】iPhone 14 Plus 128GB 256GB 512GB スマホ スマートフォン 本体 SIMフリー ミッドナイト (PRODUCT)RED スターライト…
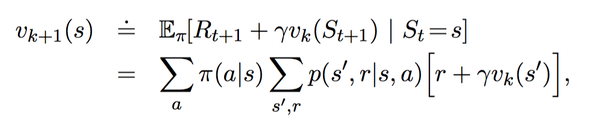
DQN从入门到放弃学习总结(2)1、动作价值函数:2、最优价值函数 3、策略迭代 policy iteration 4、价值迭代5、策略迭代和价值迭代的区别