Similar to 人間のフィードバックによる強化学習
マルコフ確率場
Markov random field
Multi-Step Super-Resolution
メタ学習
Meta learning (computer science)
ランダムフーリエ特徴量
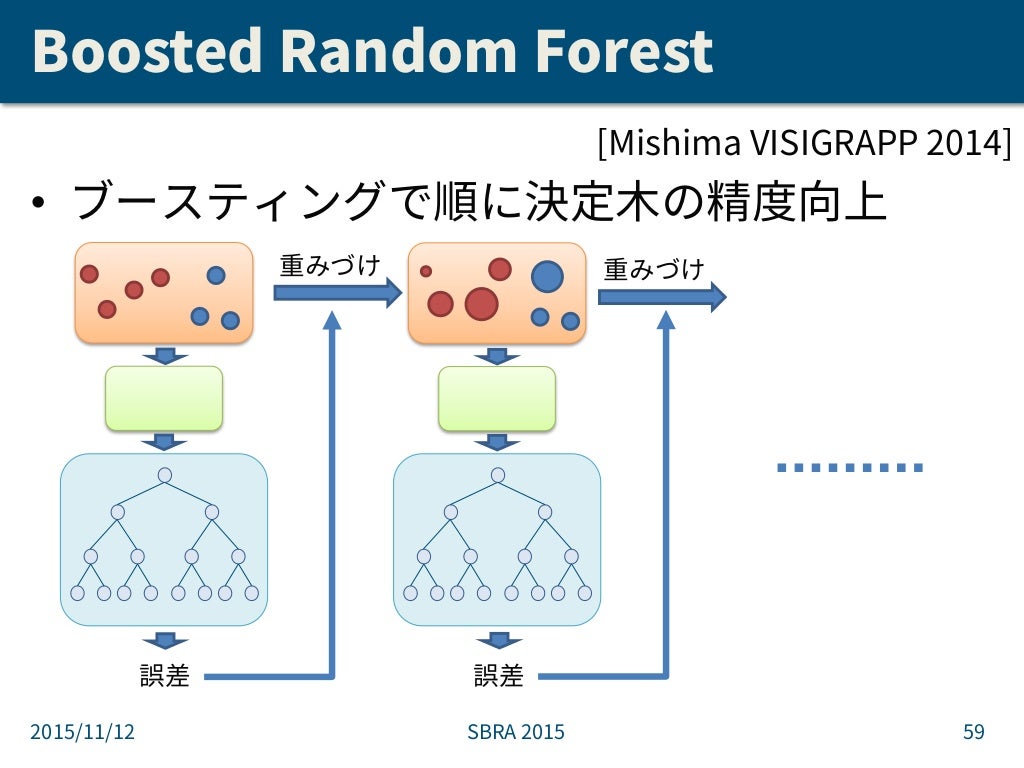
ランダムフォレスト
Random forest
LoRA
LoRA
ロボティック・プロセス・オートメーション
Robotic process automation
サロゲートモデル
Surrogate model
ハイパーパラメータ (機械学習)
Hyperparameter (machine learning)
半教師あり学習
Weak supervision
特徴抽出
Feature engineering
Q学習
Q-learning
SARSA法
State–action–reward–state–action
エンドツーエンドの強化学習
End-to-end reinforcement learning
時間差分学習
Temporal difference learningベイズ強化学習
モデルフリー (強化学習)
Model-free (reinforcement learning)
分布ソフト・アクター・クリティック法
Distributional Soft Actor Critic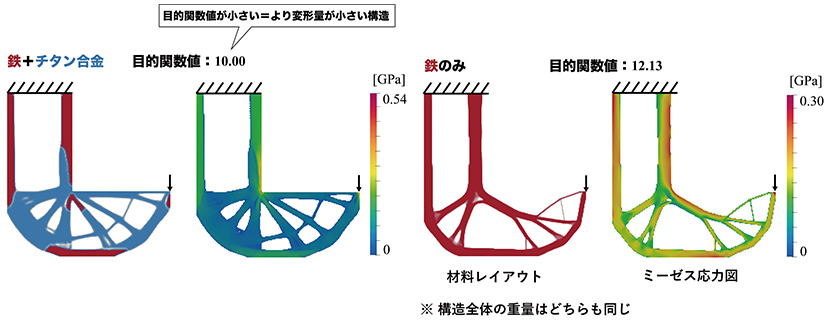
近接方策最適化
Proximal policy optimization
人工知能
Artificial intelligenceTemplate:主な人工知能
Template:Generative AI
Template:人工知能による存亡リスク
Template:Existential risk from artificial intelligence
生成的人工知能の一覧
AI JIMY Converter
AI JIMY Paperbot

AIセーフティ
AI safetyApple Intelligence
Apple IntelligenceDABUS
DABUS